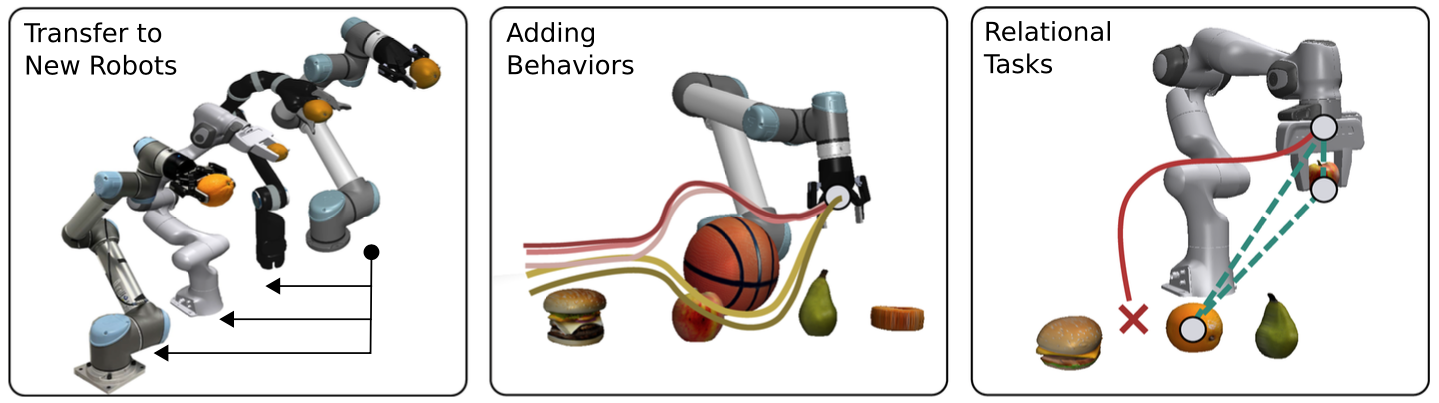

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.
Training language-conditioned imitation learning policies is typically time-consuming and resource-intensive. Additionally, the resulting controllers are tailored to the specific robot they were trained on, making it difficult to transfer them to other robots with different dynamics. To address these challenges, we propose a new approach called Hierarchical Modularity, which enables more efficient training and subsequent transfer of such policies across different types of robots. The approach incorporates Supervised Attention which bridges the gap between modular and end-to-end learning by enabling the re-use of functional building blocks. In this contribution, we build upon our previous work, showcasing the extended utilities and improved performance by expanding the hierarchy to include new tasks and introducing an automated pipeline for synthesizing a large quantity of novel objects. We demonstrate the effectiveness of this approach through extensive simulated and real-world robot manipulation experiments.
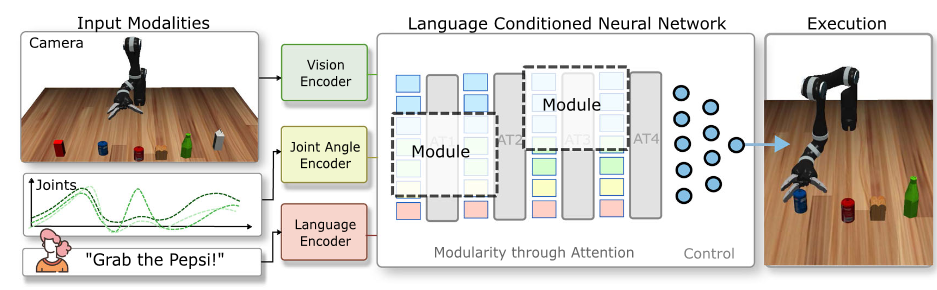
This figure is a very typical imitation learning pipeline. The inputs are usually defined as an RGB image, the joint angles, and the language as instruction. The output is the action trajectory. With expert demonstrations, we can train an end-2-end policy network. Many works have shown success using this paradigm, and have shown a lot of great results. However, they also exhibit the characteristics of being data hungry. They usually require a lot of training data although robot data is usually hard to acquire. Therefore, this work focuses on finding ways to make language conditioned imitation learning more data efficient. We propose to still train an end-2-end model. However, by designing specific attention techniques which routes the information flow in desired manner, we created different submodules that account for different subtasks within the same network.
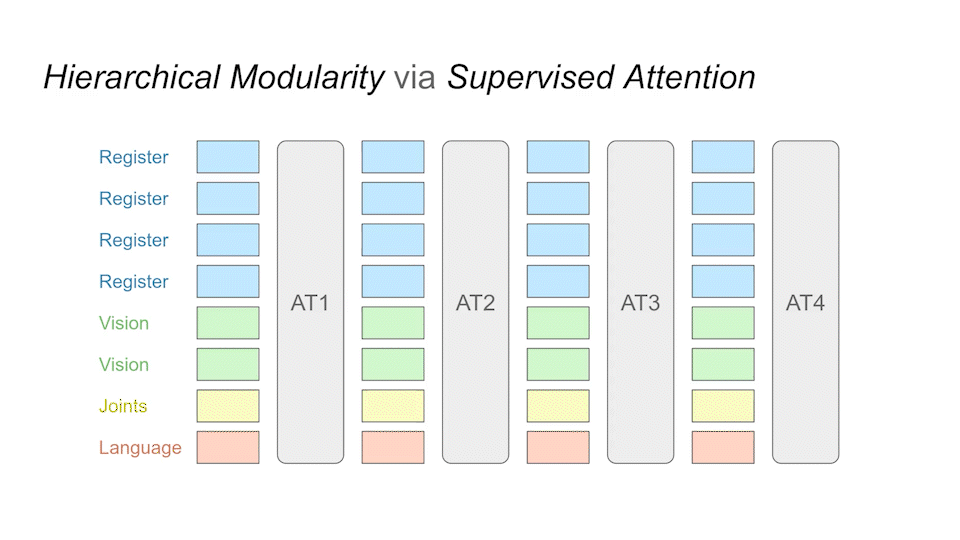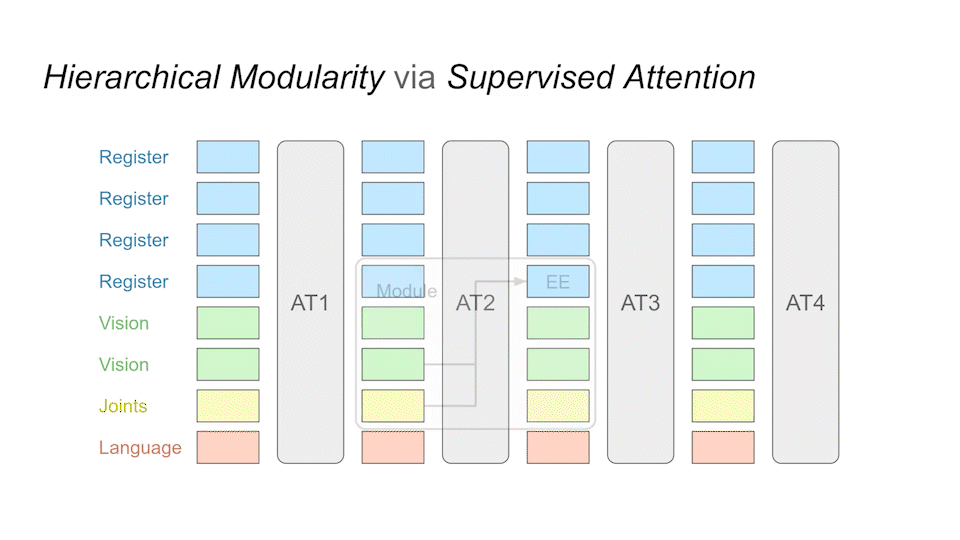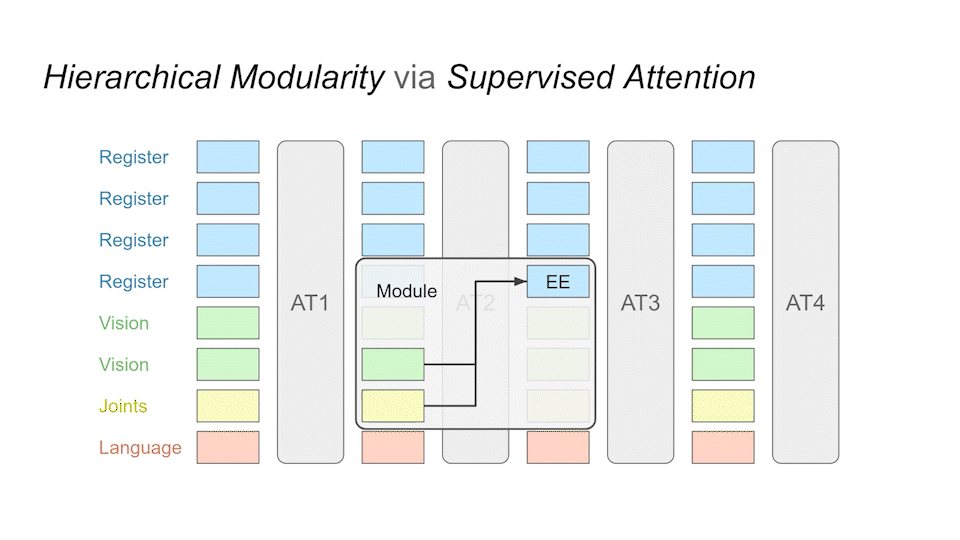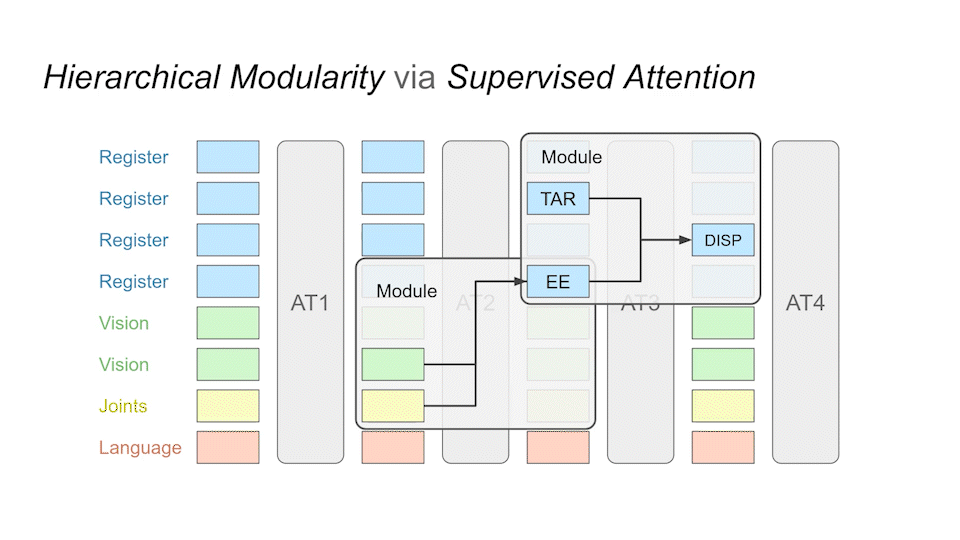
We implement building blocks called sub-modules that realize specialized sub-tasks. These modules are implemented in the same transformer. As an example, the EE module is assigned the task of tracking the end-effector, while the DISP module is supposed to calculate the displacement between the target object and the end-effector.
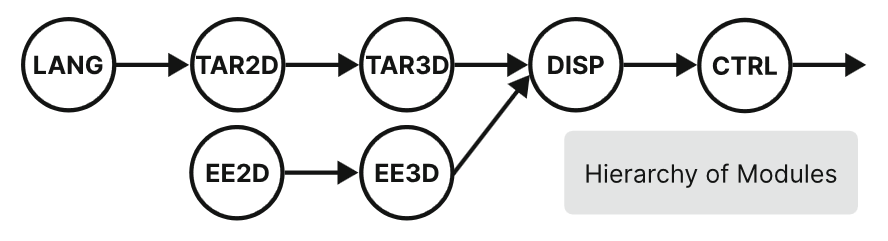
Since we are able to create multiple sub-modules, we can connect them to a hierarchy for desired tasks. The hierarchy shown here is a very typical example for common manipulation tasks. Each node here is a submodule and the arrow represents the attention token embeddings between attention layers. Firstly we understand the language input, from which we can find target location. After also finding end-effector location, we can then calculate the displacement between them, which in the end will contribute to the controller sub-module that outputs the final action trajectory.

After training on a task, we can easily finetune some modules. For example, finetuning the CTRL (motion control) module gives us the opportunities to transfer the trained policy to an unseen robot embodiment.
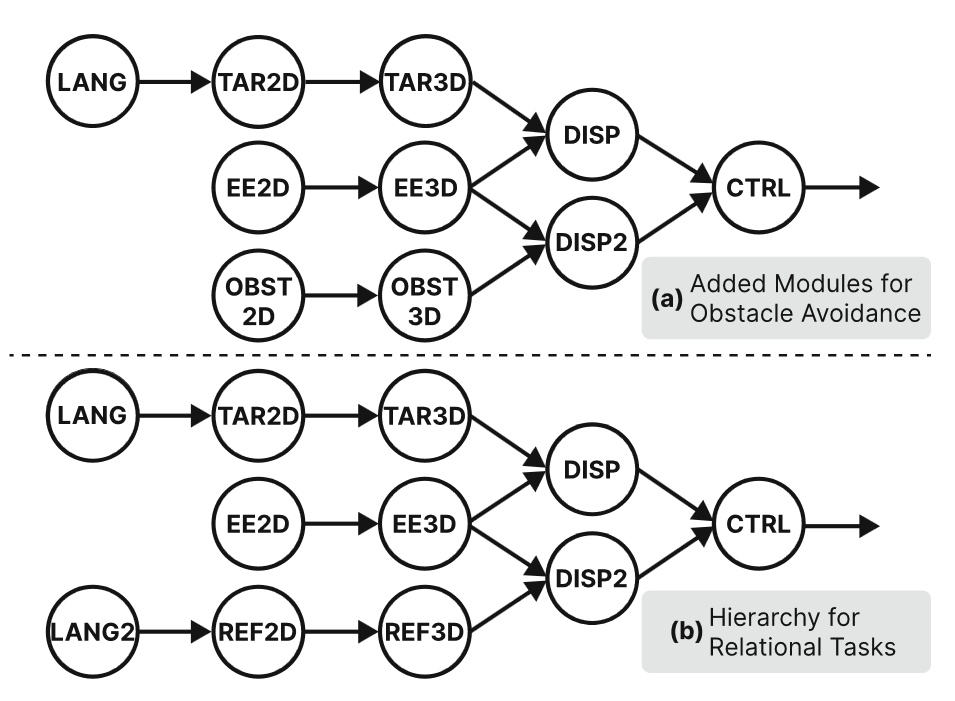
Because of the hierarchical nature, we can add new modules to the whole architecture easily. For example, we add a branch of modules for obstacle avoidance. Similarly, we detect the obstacle first, and calculate its displacement from the end-effector, which contributes to the controller module to generate the trajectory. Another case (b) is the hierarchy for relational tasks, i.e., "Put A to the right of B".

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.

Our method is data-efficient for training and transfer. This is achieved by forming sub-modules through attention layers in a cascading manner.
@article{zhou2023learning,
title={Learning modular language-conditioned robot policies through attention},
author={Zhou, Yifan and Sonawani, Shubham and Phielipp, Mariano and Ben Amor, Heni and Stepputtis, Simon},
journal={Autonomous Robots},
pages={1--21},
year={2023},
publisher={Springer}
}